...
TRANSFER, ERROR, Copy, failed, with, mode, pull, with, error, copy, Could, not, get, the, delegation, id, Could,
not, get, proxy, request, Error, fault, SOAP-ENVServer, no, subcode, HTTP, Not, Found, Detail, .
Processing Phase
Word2Vec is a Machine Learning algorithm used in Natural Language Processing applications to compute vector representations of words (word embedding). It was developed in 2013 by a Google team made of Tomas Mikolov, Kai Chen, Greg Corrado and Jeffrey Dean. Why do we need Word Embeddings? Let us consider the words file, directory, cat: how can an algorithm know that file can be related to directory while it would hardly appear with cat? Machine Learning algorithms are not good at dealing with strings but they can achieve astonishing results with numbers: this is the reason for word embedding. Mikolov's team found that "similarity of words representations goes beyond simple syntactic regularities". They showed, for example, thatthe vectorial sum of King - Man + Woman results in a vector that is closest to the vector representation of the word Queen. The success of this algorithm resides not only in the accuracy it can achieve, but also in the time required; indeed it is able to learn high quality word vectors from billions of words in less than a day.
Word2Vec is a shallow network, that is a network made of an input layer, an output layer and one hidden layer:
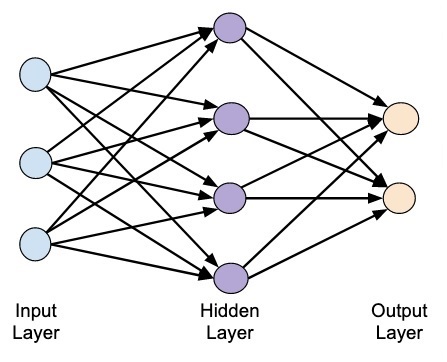
It is an example of Prediction based Embeddings, because it encodes the probability of a word given its context (or vice-versa). Having a high-level insight about the underlying process, we can say that the algorithm trains a simple neural network (NN) on a certain objective (fake task), but we are not going to use that NN for the task we trained it on. Instead, the goal is actually just to learn the weights of the hidden layer: these weights are actually the "word vectors" we are looking for. Having a resume:
- fake task: learning the probability for a certain sequence of tokens;
- goal: obtaining the parameters that minimize the error in the fake task.
Word2Vec can work with two different architectures:
- Continuous Bag-of-Words (CBOW): predicts the center word based on surrounding context words, where the context is m (given as hyperparameter) words before and after a center word;
- Continuous Skip-gram predicts the context given a word, where, again, the context is m words before and after the input word.
Both architectures are "continuous" meaning they use a continuous distributed representations of the context.
References
Attachments
...