...
In particular, Machine Learning tools are models which have enough capacity to define their own internal representation of data to accomplish two main tasks : learning from data and make predictions without being explicitly programmed to do so.
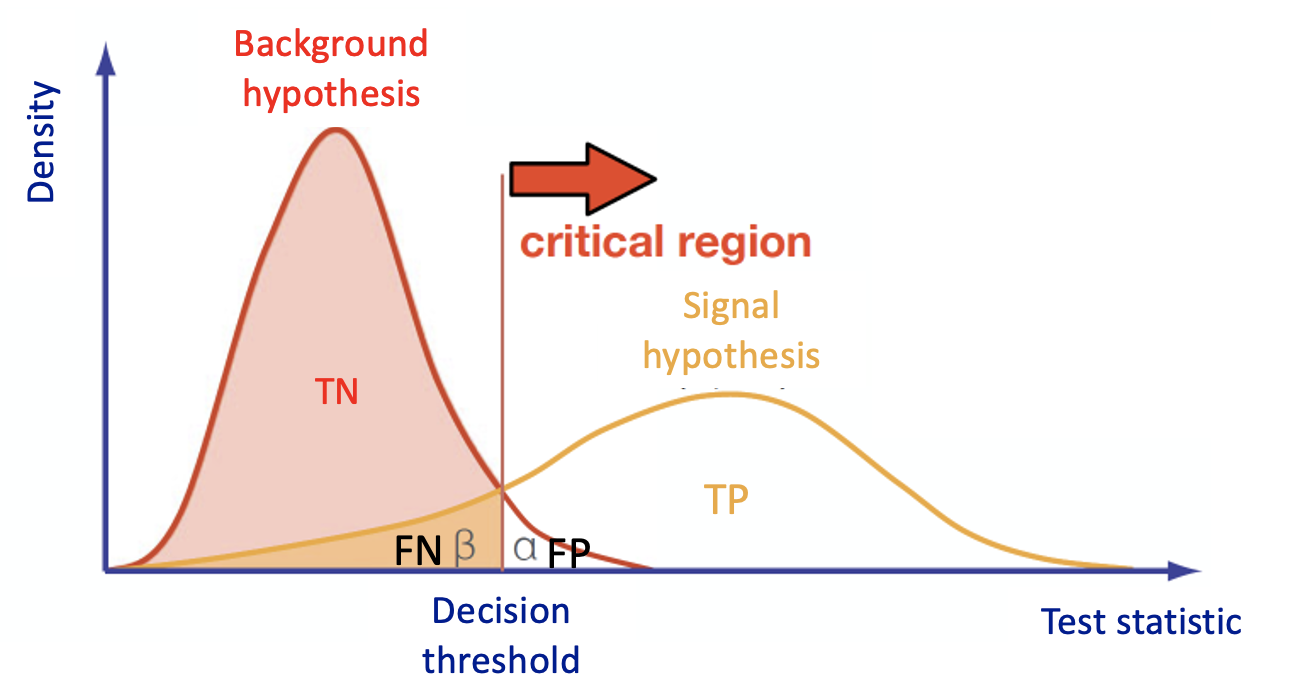
In the case of binary classification, firstly the algorithm is trained with two datasets:
- one that contains events distributed according to the null (in our case signal - there exist other conventions in actual physics analyses) hypothesis
;
- another one according to the alternative (in our case background) hypothesis
.
Then the algorithm must learn how to classify new datasets (the test dataset in our case).
This means that we have the same set of features (random variables) with their own distribution on the and
hypotheses.
To obtain a good ML classifier with high discriminating power, we will follow the following steps:
Training (learning): a discriminator is built by using all the input variables. Then, the parameters are iteratively modified by comparing the discriminant output to the true label of the dataset (supervised machine learning algorithms, we will use two of them). This phase is crucial: one should tune the input variables and the parameters of the algorithm!
- As an alternative, algorithms that group and find patterns in the data according to the observed distribution of the input data are called unsupervised learning.
- A good habit is training multiple models with various hyperparameters on a “reduced” training set ( i.e. the full training set minus the so-called validation set), and then select the model that performs best on the validation set.
- Once, the validation process is over, you can re-train the best model on the full training set (including the validation set), and this gives you the final model.
Test: once the training has been performed, the discriminator score is computed in a separated, independent dataset for both
- A comparison is made between test and training classifier and their performances (in terms of ROC curves) are evaluated.
- If the test fails and the performance of the test and training are different, this could be a symptom of overtraining and our model can be considered not good!
How to execute it
Use Googe Colab
...