...
Introduction to the Random Forest algorithm
Decision Trees and their extension Random Forests are robust and easy-to-interpret machine learning algorithms for classification tasks.
...
One of the biggest advantages of using Decision Trees and Random Forests is the ease in which we can see what features or variables contribute to the classification or regression and their relative importance based on their location depthwise in the tree.
Decision Tree
A decision tree is a sequence of selection cuts that are applied in a specified order on a given variable dataset.
...
The gain due to the splitting of a node A into the nodes B1 and B2, which depends on the chosen cut, is given by ΔI=I(A)-I(B1)-I(B2) , where I denotes the adopted metric (G or E, in case of the Gini index or cross-entropy introduced above). By varying the cut, the optimal gain may be achieved.
Pruning Tree
A solution to the overtraining is pruning, which is eliminating subtrees (branches) that seem too specific to the training sample:
- a node and all its descendants turn into a leaf
- stop tree growth during the building phase
Be Careful: early stopping conditions may prevent from discovering further useful splitting. Therefore, grow the full tree and when results from subtrees are not significantly different from results coming from the parent one, prune them!
From tree to the forest
The random forest algorithm consists of ‘growing’ a large number of individual decision trees that operate as an ensemble from replicas of the training samples obtained by randomly resampling the input data (features and examples).
...
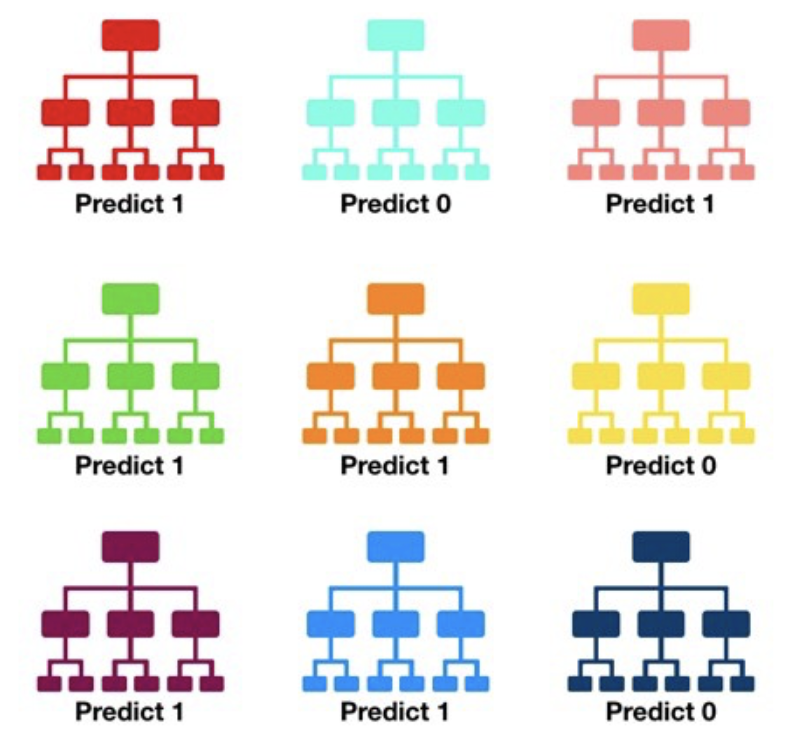
Its main characteristics are:
No minimum size is required for leaf nodes. The final score of the algorithm is given by an unweighted average of the prediction (zero or one) by each individual tree.
Each individual tree in the random forest splits out a class prediction and the class with the most votes becomes our model’s prediction.
As a large number of relatively uncorrelated models (trees) operating as a committee,this algorithm will outperform any of the individual constituent models. The reason for this wonderful effect is that the trees protect each other from their individual errors (as long as they don’t constantly all err in the same direction). While some trees may be wrong, many other trees will be right, so as a group the trees are able to move in the correct direction.
In a single decision tree, we consider every possible feature and pick the one that produces the best separation between the observations in the left node vs. those in the right node. In contrast, each tree in a random forest can pick only from a random subset of features (bagging).This forces even more variation amongst the trees in the model and ultimately results in lower correlation across trees and more diversification.
...