If your use case has needs related to parallel computing, i.e. multinode-MPI or needs special computing resources such as Intel Manycore or NVIDIA GPUs, probably you need to access the CNAF HPC cluster, which is a small cluster (about 100TFLOPS) but with special HW available [9]. The user needs a different account, in the HPC group, to access the HPC resources. This cluster is accessible via the LSF batch system for which you can find the instruction here [10] and Slurm Workload Manager which will be introduced hereafter. Please, contact User Support (user-support<at>lists.cnaf.infn.it) if interested.
- Access
Access the cluster logging into: ui-hpc.cr.cnaf.infn.it from bastion. You have to use the same credentials you used to log into bastion.
Your home directory will be: /home/HPC/<your_username> and is shared among all the cluster nodes.
No quotas are currently enforced on the home directories and about only 4TB are available in the /home partition. In the case you need more disk space for data and checkpointing every user can access the following directory: /storage/gpfs_maestro/hpc/user/<your_username>/ which is on a shared gpfs storage.
Please, do not leave huge unused files in both home directories and gpfs storage areas. Quotas will be enforced in the near future.
for support, contact us (hpc-support@lists.cnaf.infn.it).
- SLURM architecture
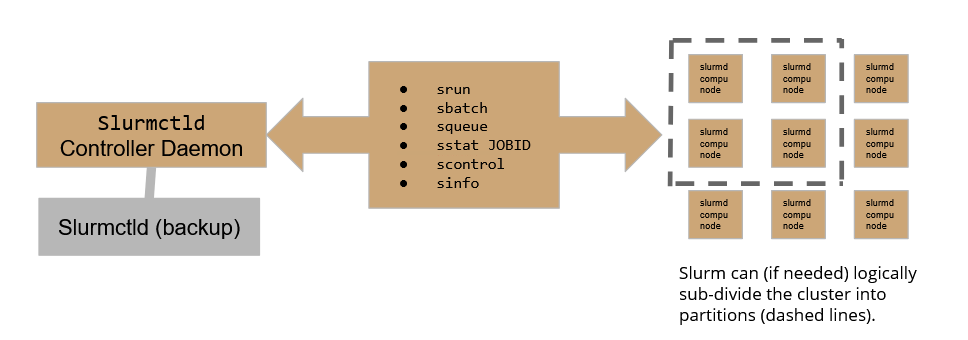
On our HPC cluster, the user can leverage two queues:
<slurmprova> should be used for CPU-exclusive jobs (i.e. jobs that do not use GPU)
<slurmprovaGPU> should be used for CPU+GPU jobs.
- Check the cluster status with SLURM
you can check the cluster status in two ways:
- using the sinfo -N -l command you can list nodes and few properties such as status and hardware capabilities
2. using the scontrol show nodes command you can obtain a detailed “per node” list