Author(s)
| Name | Institution | Mail Address | Social Contacts |
|---|---|---|---|
| Federica Legger | INFN Sezione di Torino | federica.legger@to.infn.it | N/A |
| Micol Olocco | Università di Torino | micol.olocco@edu.unito.it | N/A |
How to Obtain Support
| federica.legger@to.infn.it, micol.olocco@edu.unito.it | |
| Social | N/A |
| Jira | ??? |
General Information
| ML/DL Technologies | NLP |
|---|---|
| Science Fields | High Energy Physics, Computing |
| Difficulty | Medium |
| Language | English |
| Type | fully annotated / runnable / external resource |
Software and Tools
| Programming Language | Python |
|---|---|
| ML Toolset | Word2Vec + Rake + sklearn |
| Additional libraries | panda |
| Suggested Environments | INFN-Cloud VM, bare Linux Node, Google CoLab |
Needed datasets
| Data Creator | FTS |
|---|---|
| Data Type | Error messages |
| Data Size | 8 MB compressed |
| Data Source |
Short Description of the Use Case
The Worldwide LHC Computing Grid (WLCG) project is a global collaboration of around 170 computing centres in more than 40 countries, linking up national and international grid infrastructures. The mission of the WLCG project is to provide global computing resources to store, distribute and analyse the ~50-70 Petabytes of data expected every year of operations from the Large Hadron Collider (LHC) at CERN. The CERN File Transfer System (FTS) is one of the most critical services for WLCG. FTS is a low level protocol used to transfer data among different sites. FTS sustains a data transfer rate of 20-40 GB/s, and it transfers daily a few millions files.
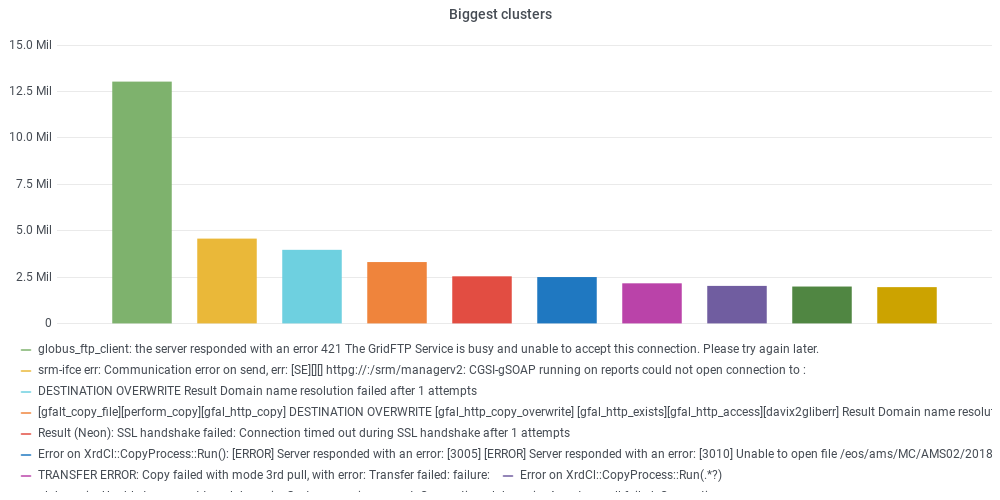
If a transfer fails, an error message is generated and stored. Failed transfers are of the order of a few hundred thousand per day. Understanding and possibly fixing the cause of failed transfers is part of the duties of the experiment operation teams. Due to the large number of failed transfers, not all can be addressed. We developed a pipeline to discover failure patterns from the analysis of FTS error logs. Error messages are read in, cleaned from meaningless parts (file paths, host names), and the text is analysed using NLP (Natural Language Processing) techniques such as word2vec. FInally the messages can be grouped in clusters based on the similarity of their text using the Levenshtein distance or using ML algorithms for unsupervised clustering such as DBSCAN. The biggest clusters and their relationship with the host names with largest numbers of failing transfers is presented in a dedicated dashboard for the CMS experiment (access to the dashboard requires login with CERN SSO). The clusters can be used by the operation teams to quickly identify anomalies in user activities, tackle site issues related to the backlog of data transfers, and in the future to implement automatic recovery procedures for the most common error types.
How to execute it
Way #1: Use Jupyter notebooks from an INFNCloud Virtual machine
Once you have a deployment with JupyterHub on INFN Cloud, you can open a terminal and clone this github repo. Then execute the notebook in
TestsINFNCloud/test_clusterLogs/NLP_example.ipynb
The input file can be found in zipped form in the github repo (message_example.zip), or read in from Minio.