-
Created by
 Andrea Rendina, last updated by Carmelo Pellegrino on Nov 11, 2025
2 minute read
Andrea Rendina, last updated by Carmelo Pellegrino on Nov 11, 2025
2 minute read
The SluRM workload manager relies on the following scheme:
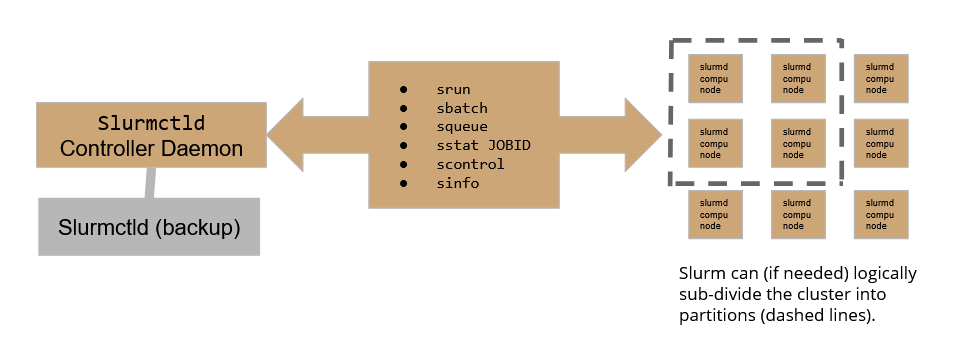
Where the Slurmctld daemon plays the role of the controller, allowing the user to submit and follow the execution of a job, while Slurmd daemons are the active part in the execution of jobs over the cluster. To assure high availability, a backup controller daemon has been configured to assure the continuity of service.
On the CNAF HPC cluster, there are currently 2 active partitions:
bare-metal-node nodes without a GPUbare-metal-GPU nodes with 4 nVidia H100 GPUs
Check the cluster status with SLURM
You can check the cluster status using the sinfo -N command which will print a summary table on the standard output.
The table shows 4 columns: NODELIST, NODES, PARTITION and STATE.
- NODELIST shows node names. Multiple occurrences are allowed since a node can belong to more than one partition
- NODES indicates the number of machines available.
- PARTITION which in slurm is a synonym of "queue" indicates to which partition the node belongs. If a partition name comes with an ending asterisk, it means that that partition will be considered the default one to run the job, if not otherwise specified.
- STATE indicates if the node is not running jobs ("idle"), if it is in drain state ("drain") or if it is running some jobs ("allocated").
For instance:
-bash-4.2$ sinfo -N PARTITION AVAIL TIMELIMIT NODES STATE NODELIST bare-metal-nodes* up infinite 1 drain* hpc-f01-05-16 bare-metal-nodes* up infinite 3 drain hpc-f01-06-[23,26,29] bare-metal-nodes* up infinite 18 idle hpc-f01-05-[03,05,09,13,19,22,25,28,31],hpc-f01-06-[01,03,05,07,09,11,14,17,20] bare-metal-nodes* up infinite 2 down hpc-f01-05-[01,07] bare-metal-GPU up infinite 1 drain* hpc-f01-05-16 bare-metal-GPU up infinite 3 drain hpc-f01-06-[23,26,29] bare-metal-GPU up infinite 10 idle hpc-f01-05-[13,19,22,25,28,31],hpc-f01-06-[11,14,17,20] [...]